z-Transformation
Das Thema »z-Transformation« kann als Vorkurs zur Normalverteilung verstanden werden und wird allen empfohlen, die mit der z-Transformation bisher wenig oder gar nichts anzufangen wissen. Die z-Transformationen (gern auch nur z-Wert genannt) bildet die Basis zum Verständnis der Normalverteilung und wird dort vorausgesetzt.
Du benötigst Unterstützung bei einer statistischen Auswertung oder eine Beratung? ProStat unterstützt dich professionell, schnell und freundlich. Du erreichst uns direkt per Telefon 0175 – 810 35 20 oder über das Kontaktformular.
In diesem Wissensthema klären wir, was eine Verteilung ist und wie man Daten z-transformiert und standardisiert. Anhand eines Beispiels verdeutlichen wir die Anwendung der z-Transformation.
Was ist eine Verteilung?
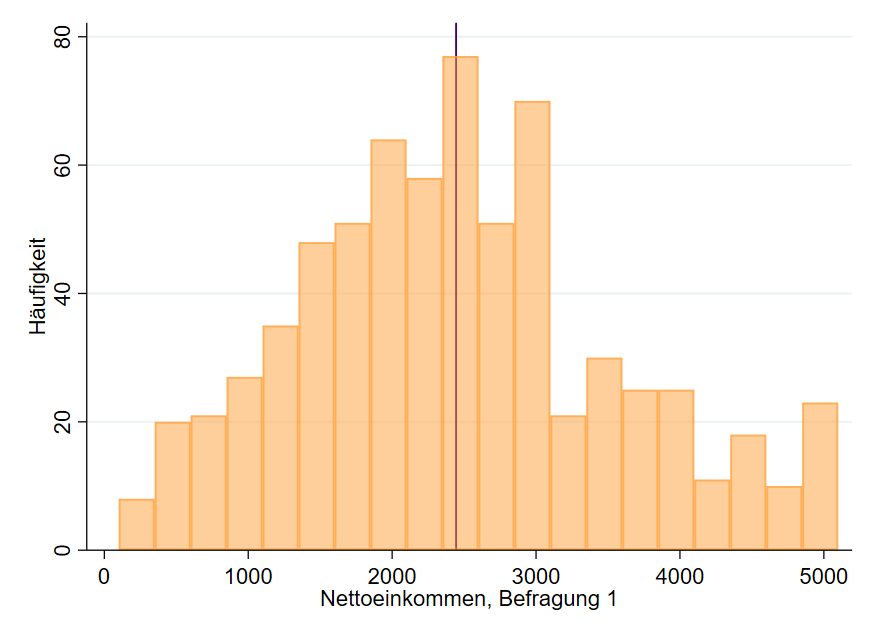
Die grafische Darstellung von Daten ist die einfachste Möglichkeit, sich einen ersten statistischen Überblick zu verschaffen. In Abbildung 1 sehen wir die Ergebnisse einer Umfrage mit $N=693$ Probanden, die zu ihrem Nettoeinkommen pro Monat befragt wurden. Der Mittelwert des Nettoeinkommens beträgt $\overline{x}=2444.39$ € und ist mit einer lila Linie dargestellt. Diese Form der Verteilung heißt Histogramm: Die Höhe der Balken gibt an, wie häufig eine bestimmte Gruppe (Balken) vorkommt. Ein Balken selbst fasst Einkommen in einer Gruppe zusammen, was die Besonderheit des Histogramms ist.
Verschiedene Fragen sind an dieser Stelle bereits möglich:
- Wie wahrscheinlich ist es, mehr als 4000 € pro Monat zu verdienen? Der Blick auf Abbildung 1 sagt uns, dass dies eher »unwahrscheinlich« ist, weil es nur wenige und nicht sehr hohe Balken ab 4000 € gibt.
- Wie wahrscheinlich ist es, dass ein Proband exakt 2500 € verdient (der Balken »im« Mittelwert)? Dies scheint »eher wahrscheinlich«, da der Balken höher als die anderen ist.
- Wie wahrscheinlich ist es, dass ein Proband zwischen 2000 € und 3000 € verdient?
Hinter Frage 3 steckt statistisch gesehen folgende Frage: Wie groß ist die Fläche der Balken zwischen 2000 € und 3000 € im Vergleich zu Gesamtfläche aller Balken? Um dies zu beantworten, müssen wir die Häufigkeiten der Balken kennen, was eine Statistiksoftware für uns erledigt.
Zwischen 2000 und 3000 € liegen $N=298$ Probanden. Da wir wissen, wie viele Probanden insgesamt ein Nettoeinkommen angegeben haben ($N=693$) können wir den Anteil (der Fläche) mit $\frac{298}{693}=0.430$, also auf 43.0 % berechnen. Die Antwort auf unsere Frage lautet daher: Es ist recht wahrscheinlich, dass ein Proband zwischen 2000 € und 3000 € verdient, da 43.0 % der Probanden in dieser Einkommensspanne liegen. Es besteht – statistisch gesprochen – eine Chance von 43 %, dass jemand zwischen 2000 € und 3000 € verdient.
Eine Verteilung zeigt uns also zunächst inhaltliche Informationen einer Variablen an, mit Hilfe derer sich einfache statistische Aussagen treffen lassen.
Vergleich zwischen Verteilungen
Stellen wir uns vor, wir waren Bestandteil von Befragung 1 (Abbildung 1), also einer der $N=693$ Probanden, und wir verdienen 2000 € Netto im Monat. Damit liegen wir unterhalb des Durchschnitts ($\overline{x}=2444.39$ €). In einer zweiten Umfrage mit $N=442$ Probanden (Abbildung 2, lila) nehmen wir erneut teil und schauen uns die Ergebnisse an.
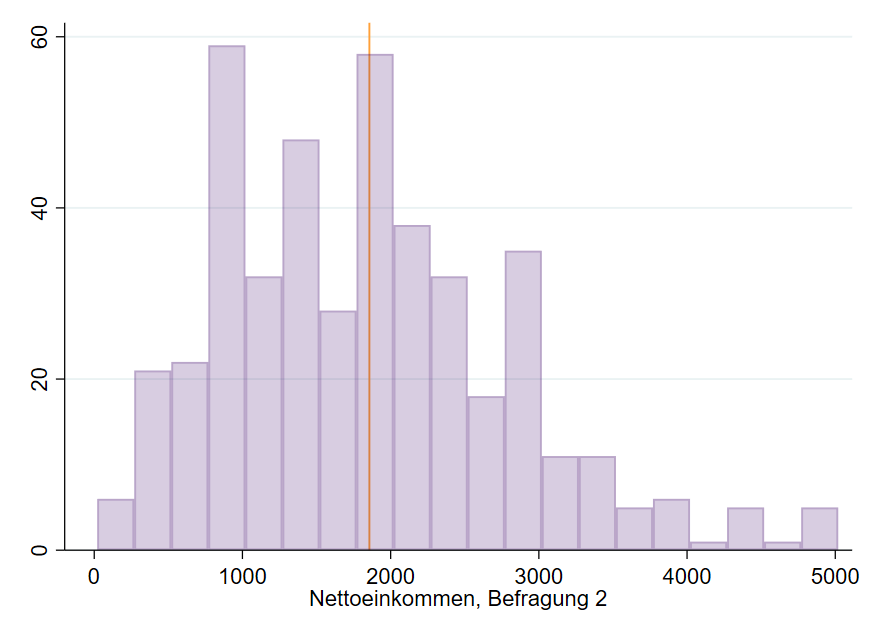
Uns selbst fällt sofort auf, dass wir mit 2000 € über dem Durchschnitt von $\overline{x}=1856.61$ € liegen, wenn auch knapp. Außerdem sind Einkommen über 4000 € weniger wahrscheinlich als in der ersten Befragung, da weniger hohe Balken zu finden sind.
Die Frage, wie groß die Fläche zwischen 2000 € und 3000 € ist – also die Frage, wie wahrscheinlich es ist, in diesem Einkommensbereich zu liegen – beantworten wir mit $\frac{150}{442}=0.339$. Auch hier berechnen wir die Anzahl der Probanden im Bereich 2000 € – 3000 € mit $N=150$ durch eine Statistiksoftware und müssen nicht mühsam die Balken abzählen. Die Chance, zwischen 2000 € und 3000 € zu verdienen, liegt bei 33.9 % und damit ca. 10%-Punkte unter der ersten Befragung.
Zwei voneinander unabhängig geführte Befragungen enthalten immer andere Einkommenswerte und sehen dadurch grafisch auch anders aus. Oftmals wird davon ausgegangen, dass diese beiden Verteilungen nicht miteinander verglichen werden können, doch das ist falsch.
z-Transformation
Mithilfe der z-Transformation können wir Verteilungen vergleichen. Normalerweise, wenn die Skala der Verteilungen nicht die Gleiche ist. In unserem Fall wird das Einkommen immer in Euro gemessen und hat damit die gleiche Skaleneinheit. Aber auch hier ist eine z-Transformation zum Vergleich sinnvoll, da sich die beiden Befragungen in ihrem Mittelwert und der Standardabweichung unterscheiden.
Bei einer z-Transformation wird von jedem erhobenen Wert (aktuell: individuelles Einkommen) der Mittelwert der Verteilung abgezogen und durch die Standardabweichung der Verteilung geteilt.
$$z=\frac{x-\overline{x}}{s}$$
Für unsere beiden Befragungen liegen folgende Informationen vor (Tabelle 1).
Tabelle 1: Deskriptive Statistik Befragung 1 und 2
| Statistik | Befragung 1 | Befragung 2 |
|---|---|---|
| N | 693 | 442 |
| $\overline{x}$ | 2444.39 | 1856.61 |
| s | 1120.883 | 979.507 |
Abbildung 3 zeigt in der oberen Zeile (orange links und lila rechts) das Nettoeinkommen von Befragung 1 und 2. Darunter findet sich jeweils das Histogramm der z-transformierten Werte. Nach der Transformation gilt für beide Verteilungen, dass der Mittelwert Null ($\overline{x}=0$) ist. Diese statistische Methode wird Zentrierung am Mittelwert oder Mittelwertzentrierung genannt ($x-\overline{x}$). Die Standardabweichung der z-Werte ist $s=1$, da nach der Zentrierung durch die Standardabweichung geteilt wurde.
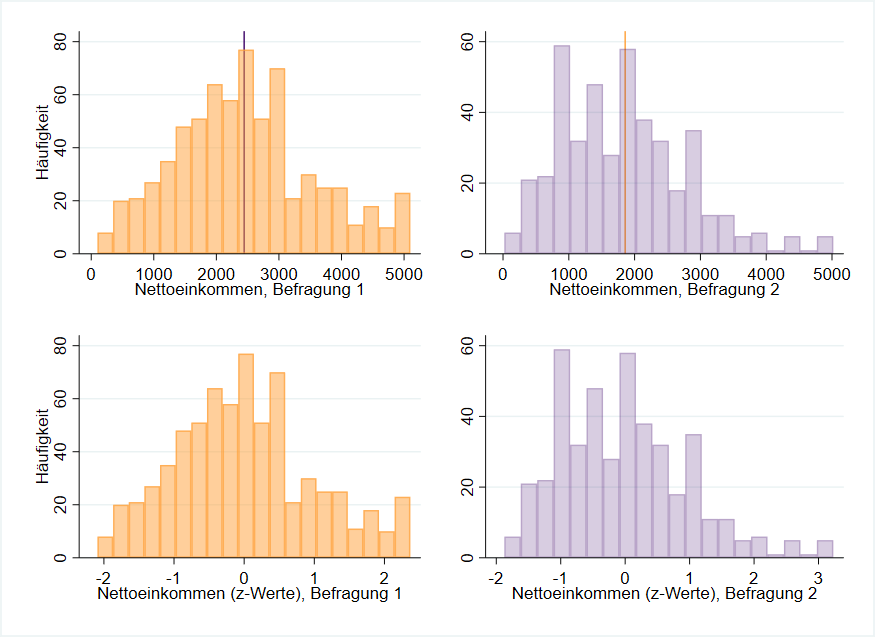
Was hat sich allerdings nicht verändert? Ein Blick auf die beiden Grafiken von Befragung 1 (orange) macht deutlich, dass sich am Aussehen der Verteilung nichts verändert hat. Die Transformation führt nicht dazu, dass sich die Häufigkeiten der Originalwerte verändern. Wir erinnern uns, dass zwischen 2000 € und 3000 € bei Befragung 1 (orange) $N=298$ Probanden liegen. Dies ist auch jetzt noch der Fall.
Doch die Werte für 2000 € und 3000 € haben sich verändert. Wenn wir diese beiden Einkommen mit den statistischen Informationen von Befragung 1 (Tabelle 1) in die Formel der z-Transformation einsetzen, erhalten wir:
$$z_{2000}=\frac{2000-2444.39}{1120.883}=-0.396$$
$$z_{3000}=\frac{3000-2444.39}{1120.883}=0.496$$
Aus 2000 € ist $z=-0.396$ geworden und aus 3000 € $z=0.496$. Die x-Achse verändert sich von Euro auf die berechneten z-Werte. Damit einher geht auch eine andere Interpretation der Balken. Diese zeigen die Häufigkeiten der z-Werte, welche in Einheiten der Standardabweichung ausdrücken, wie stark diese um den Mittelwert 0 streuen. Schauen wir uns dafür unser Einkommen von 2000 € an.
Mit einem z-Wert von $z=-0.396$ liegt ein Einkommen von 2000 € bei der ersten Befragung exakt 0.396 Standardabweichungen unter dem Mittelwert (negativer z-Wert), bei der zweiten Befragung liegt das Einkommen von 2000 € 0.146 Standardabweichungen über dem Mittelwert (positiver z-Wert: $z_{2000}=\frac{2000-1856.61}{979.507}=0.146$). Damit ist das Einkommen in der 2. Befragung relativ gesehen besser als in der 1. Befragung.
Um die Anwendung der z-Transformation noch besser zu verdeutlichen, ein Beispiel bei unterschiedlichen Skalen, was die häufigste Anwendung für diese Art von Transformation darstellt.
Intelligenz und Kreativität
Für einen Einstellungstest an einer Universität im Fachbereich Quantenphysik wird mit einem Test die Intelligenz über den IQ gemessen. Zusätzlich erfasst der Test die Kreativität anhand verschiedener praktischer Aufgaben und verrechnet die erreichten Punkte zu einem Score. Insgesamt $N=500$ Bewerber haben diesen Test durchlaufen. Folgende deskriptive Informationen liegen über die beiden gemessenen Eigenschaften vor (Tabelle 2).
Tabelle 2: Deskriptive Statistik von Intelligenz und Kreativität| Statistik | IQ | Kreativität (K) |
|---|---|---|
| N | 500 | 500 |
| $\overline{x}$ | 120.33 | 33.33 |
| s | 19.548 | 9.807 |
| Minimum | 72 | 0 |
| Maximum | 175 | 64 |
Als Bewerber liegen unsere individuellen Testwerte bei $IQ=118$ und einer Kreativität von $K=29$. Wir wollen nun einschätzen, wie wir uns geschlagen haben. Da Intelligenz und Kreativität nicht mit der gleichen Skala gemessen werden, fällt es uns schwer, zwischen den beiden Testergebnissen eine Relation herzustellen.
Abbildung 4 zeigt in der linken Spalte oben (orange), dass die Skala des IQs bei ca. 70 beginnt und mit ca. 180 endet (genaue Zahlen: siehe Tabelle 2 oben). Kreativität (darunter in lila) beginnt mit einem Skalenwert von 0 und endet bei ca. 65. Es liegen zwei unterschiedliche Skalen vor, die für einen Vergleich nicht herangezogen werden können. Wichtig: Dies ist bedingt durch die Skala selbst und nicht dadurch, dass die Werte für Kreativität bei ca. 60 enden. Zu besseren Veranschaulichung wurde allerdings dieses Beispiel gewählt.
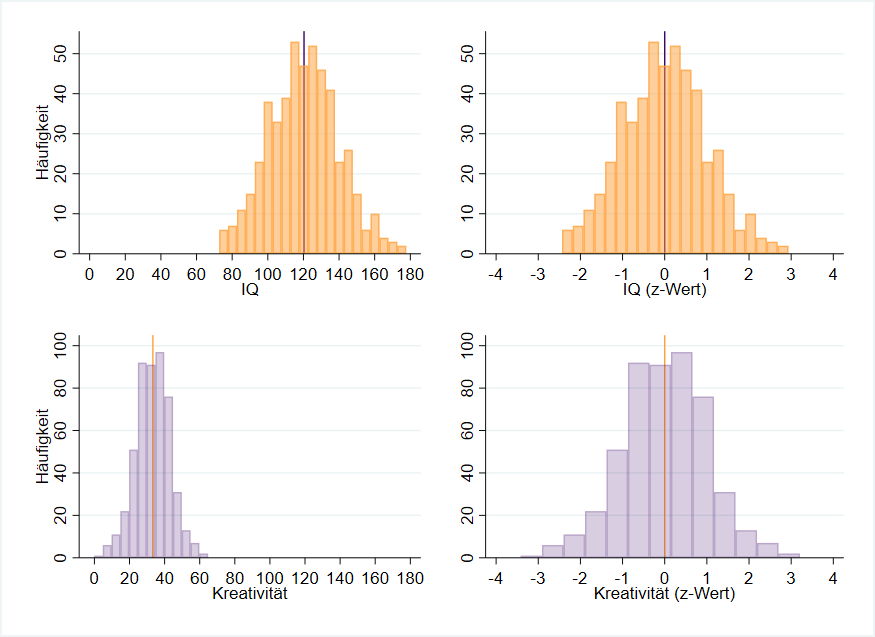
Nach der z-Transformation (rechte Spalte von Abbildung 4) der beiden Messungen erhalten wir jeweils eine neue Variable mit dem Mittelwert von 0 und einer Standardabweichung von 1. Auch hier sind die Häufigkeiten mit den Originalwerten identisch, da wir lediglich eine Transformation durchführen.
Wir haben eine gemeinsame Skalierung auf Basis der Standardabweichung geschaffen. Zudem sind die Mittelwerte identisch mit $\overline{x}=0$. Wir berechnen für unsere individuellen Testwerte jeweils den z-Wert:
$$z_{IQ=118}=\frac{118-120.33}{19.548}=-0.119$$
$$z_{K=29}=\frac{29-33.33}{9.807}=-0.442$$
Relativ gesehen ist unser Kreativitätswert der schlechteste Wert, da dieser 0.442 Standardabweichungen unter dem Durchschnitt aller Bewerber liegt, wohingegen der IQ nur 0.119 Standardabweichungen unter dem Durchschnitt liegt. Beide Werte sind sich sehr ähnlich, sodass von einem großen Unterschied nicht gesprochen werden kann. Wir sind also durchschnittlich kreativ und intelligent.
Standardisierung
Da viele Anwender Schwierigkeiten mit einer Interpretation in Standardabweichungen haben, ist es möglich, den Score der Kreativität an des IQs anzupassen (natürlich auch umgekehrt). Dafür müssen wir die berechneten individuellen z-Werte der Kreativität bei jedem Probanden ($z_K$, hier nicht aufgelistet) mit der gewünschten Standardabweichung (Ziel ist die Verteilung des IQs, daher auch $s_{IQ}$) multiplizieren und den Mittelwert des IQ ($\overline{x}_{IQ}$) hinzuaddieren:
$$z_K*s_{IQ}+\overline{x}_{IQ}=z_K*19.548+120.33$$
Diese erneute Transformation nennt man Standardisierung. Schauen wir uns beide Verteilungen an (Abbildung 5).
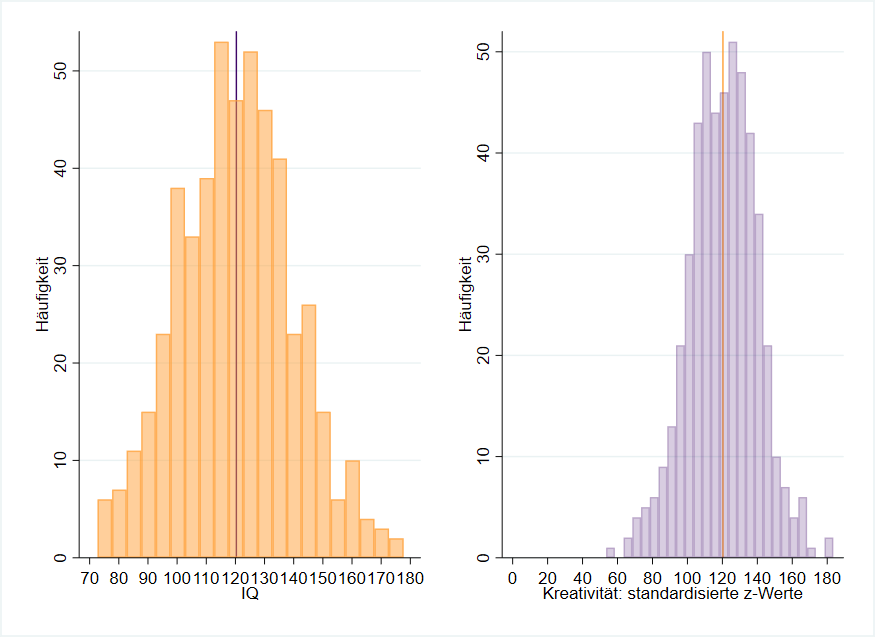
Wir haben die Werte der Kreativität mathematisch korrekt in die Verteilungsgrößen (Mittelwert und Standardabweichung) des IQ transformiert und können direkt vergleichen. Unser individueller Kreativitätswert von $K=29$, der als z-Wert $z=-0.442$ beträgt, sit standardisiert:
$$z_{std}=-0.442*19.548+120.33=111.71$$
Auf die IQ-Skala übertragen beträgt unser Kreativitätswert $K=111.71$ und liegt damit nur geringfügig unter dem Mittelwert von $\overline{x}=120.33$, der nun für beide Skalen gilt.